Performance data collection based on FSDP or MindSpeed(Megatron) on Ascend devices(zh)
在昇腾设备上基于 FSDP 或 MindSpeed (Megatron) 后端进行性能数据采集
Last updated: 12/20/2025.
这是一份在昇腾设备上基于FSDP或MindSpeed(Megatron)后端,使用GRPO或DAPO算法进行数据采集的教程。
配置
使用两级profile设置来控制数据采集
全局采集控制:使用verl/trainer/config/ppo_trainer.yaml(FSDP),或verl/trainer/config/ppo_megatron_trainer.yaml(MindSpeed)中的配置项控制采集的模式和步数。
角色profile控制:通过每个角色中的配置项控制等参数。
全局采集控制
通过 ppo_trainer.yaml 中的参数控制采集步数和模式:
global_profiler: 控制采集的rank和模式
tool: 使用的采集工具,选项有 nsys、npu、torch、torch_memory。
steps: 此参数可以设置为包含采集步数的列表,例如 [2, 4],表示将采集第2步和第4步。如果设置为 null,则不进行采集。
save_path: 保存采集数据的路径。默认值为 "outputs/profile"。
角色profiler控制
在每个角色的 profiler 字段中,您可以控制该角色的采集模式。
enable: 是否为此角色启用性能分析。
all_ranks: 是否从所有rank收集数据。
ranks: 要收集数据的rank列表。如果为空,则不收集数据。
tool_config: 此角色使用的性能分析工具的配置。
通过每个角色的 profiler.tool_config.npu 中的参数控制具体采集行为:
level: 采集级别—选项有 level_none、level0、level1 和 level2
level_none: 禁用所有基于级别的数据采集(关闭 profiler_level)。
level0: 采集高级应用数据、底层NPU数据和NPU上的算子执行详情。在权衡数据量和分析能力后,level0是推荐的默认配置。
level1: 在level0基础上增加CANN层AscendCL数据和NPU上的AI Core性能指标。
level2: 在level1基础上增加CANN层Runtime数据和AI CPU指标。
contents: 控制采集内容的选项列表,例如 npu、cpu、memory、shapes、module、stack。
npu: 是否采集设备端性能数据。
cpu: 是否采集主机端性能数据。
memory: 是否启用内存分析。
shapes: 是否记录张量形状。
module: 是否记录框架层Python调用栈信息。相较于stack,更推荐使用module记录调用栈信息,因其产生的性能膨胀更低。
stack: 是否记录算子调用栈信息。
analysis: 启用自动数据解析。
discrete: 使用离散模式。
示例
禁用采集
global_profiler:
steps: null # disable profile
端到端采集
global_profiler:
steps: [1, 2, 5]
save_path: ./outputs/profile
actor_rollout_ref:
actor: # 设置 actor role 的 profiler 采集配置参数
profiler:
enable: True
all_ranks: True
tool_config:
npu:
discrete: False
contents: [npu, cpu] # 控制采集列表,默认cpu、npu,可配置memory、shapes、module等
# rollout & ref follow actor settings
离散模式采集
global_profiler:
steps: [1, 2, 5]
save_path: ./outputs/profile
actor_rollout_ref:
actor:
profiler:
enable: True
all_ranks: True
tool_config:
npu:
discrete: True
contents: [npu, cpu] # 控制采集列表,默认cpu、npu,可配置memory、shapes、module等
# rollout & ref follow actor settings
可视化
采集后的数据存放在用户设置的save_path下,可通过 MindStudio Insight 工具进行可视化。
另外在Linux环境下,MindStudio Insight工具提供了 JupyterLab插件 形态,提供更直观和交互式强的操作界面。JupyterLab插件优势如下:
无缝集成:支持在Jupyter环境中直接运行MindStudio Insight工具,无需切换平台,无需拷贝服务器上的数据,实现数据即采即用。
快速启动:通过JupyterLab的命令行或图形界面,可快速启动MindStudio Insight工具。
运行流畅:在Linux环境下,通过JupyterLab环境启动MindStudio Insight,相较于整包通信,有效解决了运行卡顿问题,操作体验显著提升。
远程访问:支持远程启动MindStudio Insight,可通过本地浏览器远程连接服务直接进行可视化分析,缓解了大模型训练或推理数据上传和下载的困难。
如果analysis参数设置为False,采集之后需要进行离线解析:
import torch_npu
# profiler_path请设置为"localhost.localdomain_<PID>_<timestamp>_ascend_pt"目录的上一级目录
torch_npu.profiler.profiler.analyse(profiler_path=profiler_path)
进阶指南:精细化采集
背景与挑战
上述基于配置文件的采集方式虽然便捷,但在 长序列 (Long Context) 或 大全局批量 (Large Global Batch Size) 的训练场景中面临挑战。 在一个完整的训练步 (Step) 内,模型计算呈现出高频次、重复性的特征:
Rollout 阶段:序列生成 (Generate Sequence) 是一个自回归过程,涉及成千上万次 Decoder 模型的前向计算。
Training 阶段:为了控制显存峰值,verl 通常采用 Micro-Batch 策略,将庞大的数据流切分为多个微批次进行计算。
compute_log_prob (Actor/Ref):涉及多轮纯前向传播。
update_policy (Actor/Critic):涉及多轮前向与反向传播。
这种特性会导致全量 Profiling 产生海量且重复的算子记录。如下图所示:
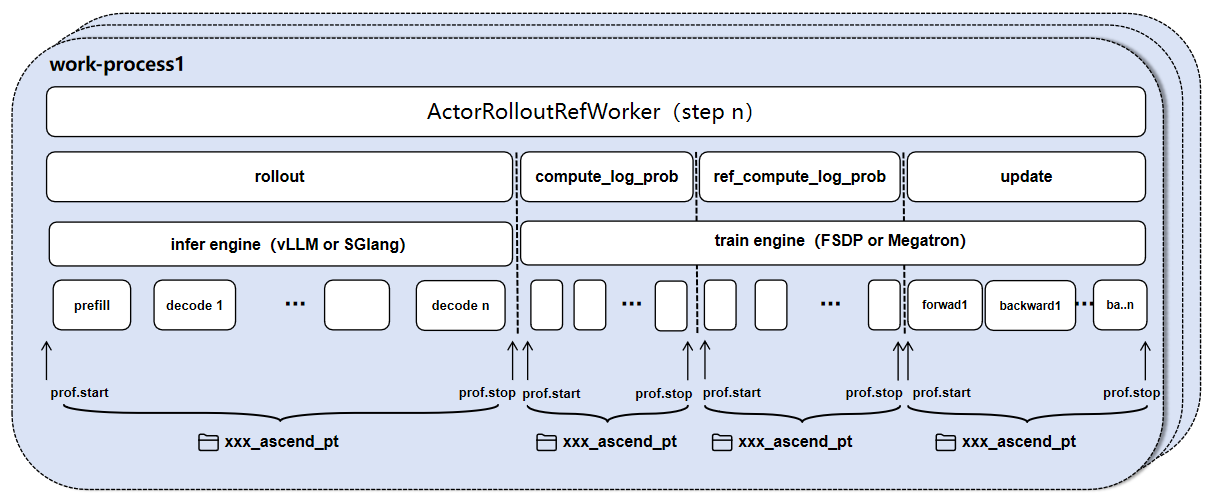
即使使用了 discrete 模式,单个阶段的性能数据文件仍可能达到数 TB,导致 解析失败 或 可视化工具卡顿 。
解决方案:关键路径采样
为了解决上述问题,我们可以采用 关键路径采样 策略:基于 torch_npu.profiler 提供的API接口,直接修改 Python 源码,仅采集具有代表性的数据片段(如特定 Decode Step 或首个 Micro-Batch)。
重要提示
本章节涉及直接修改源码。建议修改前备份文件,调试完成后恢复。
使用代码插桩采集时,请务必在
ppo_trainer.yaml或ppo_megatron_trainer.yaml中**禁用全局采集** (global_profiler: steps: null),以避免 Profiler 冲突。
1. Rollout 阶段精细化采集
对于 vLLM 或 SGLang 推理引擎,我们可以通过控制 schedule 参数来控制采集模型在特定token的前向传播性能数据。
vLLM 引擎
参考版本:vLLM v0.11.0, vLLM-Ascend v0.11.0rc1
修改文件:
vllm-ascend/vllm_ascend/worker/worker_v1.py
class NPUWorker(WorkerBase):
def __init__(self, *args, **kwargs):
# ... existing code ...
+ # Initialize profiler
+ import torch_npu
+ experimental_config = torch_npu.profiler._ExperimentalConfig(
+ profiler_level=torch_npu.profiler.ProfilerLevel.Level1,
+ export_type=torch_npu.profiler.ExportType.Db, # 可选择torch_npu.profiler.ExportType.Text格式
+ )
+ self.profiler_npu = torch_npu.profiler.profile(
+ activities=[torch_npu.profiler.ProfilerActivity.CPU, torch_npu.profiler.ProfilerActivity.NPU],
+ with_modules=False, # 采集调用栈
+ profile_memory=False, # 采集内存
+ experimental_config=experimental_config,
+ # 跳过第一步,warmup一步,采集3步,重复1次。如果想采集第30~70个decode step,可以设置为schedule=torch_npu.profiler.schedule(wait=29, warmup=1, active=30, repeat=1)
+ schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/vllm_profile", analyse_flag=True) # 采集数据保存路径,是否在线解析
+ )
+ self.profiler_npu.start()
# ... existing code ...
def execute_model(self, scheduler_output=None, intermediate_tensors=None, **kwargs):
# ... existing code ...
output = self.model_runner.execute_model(scheduler_output,
intermediate_tensors)
+ self.profiler_npu.step() # 驱动 schedule,对部分decode step进行采集
# ... existing code ...
SGLang 引擎
参考版本:SGLang master 分支
修改文件:
sglang/python/sglang/srt/model_executor/model_runner.py
# ... existing imports ...
+ import torch_npu
class ModelRunner:
def __init__(self, *args, **kwargs):
# ... existing init code ...
+ # Initialize profiler (配置同上,略)
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
+ self.profiler_npu = torch_npu.profiler.profile(
+ # ...
+ # 跳过第一步,warmup一步,采集3步,重复1次。
+ schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/sglang_profile", analyse_flag=True)
+ )
+ self.profiler_npu.start()
def forward(self, forward_batch, **kwargs):
# ... existing code ...
+ self.profiler_npu.step() # 驱动 schedule,对部分decode step进行采集
return output
2. compute_log_prob (Actor & Ref) 阶段精细化采集
该阶段计算新旧策略的概率分布。
FSDP 后端
FSDP 后端允许在 Micro-Batch 级别进行精细控制。
修改文件:
verl/workers/actor/dp_actor.py
# ... 引入依赖 ...
+ import torch_npu
class DataParallelPPOActor(BasePPOActor):
def compute_log_prob(self, data: DataProto, calculate_entropy=False) -> torch.Tensor:
+ role = "Ref" if self.actor_optimizer is None else "Actor"
+ # 准备 profiler (配置同上,略)
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
+ self.prof_npu = torch_npu.profiler.profile(
+ # ...
+ # wait=0, warmup=0, active=1: 直接采集第一个 micro-batch
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(f"./outputs/{role}_compute_log_prob", analyse_flag=True)
+ )
+ # 此函数ref和actor共用,设置role标志位来区分。如果想采集actor_compute_log_prob,可设置if role=="Actor":
+ if role=="Ref":
+ self.prof_npu.start()
for micro_batch in micro_batches:
# ... 原始计算逻辑 ...
with torch.no_grad():
entropy, log_probs = self._forward_micro_batch(...)
+ # 驱动 schedule,对micro batch进行采集
+ if role=="Ref":
+ self.prof_npu.step()
# ...
Megatron 后端
Megatron 后端的 Micro-Batch 调度由框架内部管理,暂不支持通过简单的代码插桩进行 Micro-Batch 级别的精细化采集。建议使用全局配置进行采集。
3. update_policy (Actor & Critic) 阶段精细化采集
Update 阶段包含前向和反向传播。
FSDP 后端
FSDP 后端支持设置对 Mini-Batch 和 Micro-Batch 的粒度进行采集。
修改文件:
verl/workers/actor/dp_actor.py
# ... 引入依赖 ...
+ import torch_npu
class DataParallelPPOActor(BasePPOActor):
def update_policy(self, data: DataProto):
+ # 准备 profiler (配置同上,略)
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
+ self.prof_npu = torch_npu.profiler.profile(
+ # ...
+ # 仅采集第一个 Mini Batch(包含所有 Micro-Batch 的计算和一次优化器更新)
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/fsdp_actor_update_profile", analyse_flag=True)
+ )
+ self.prof_npu.start()
# ... PPO Epochs 循环 ...
for _ in range(self.config.ppo_epochs):
# ... Mini Batch 循环 ...
for batch_idx, mini_batch in enumerate(mini_batches):
# ... mini_batches 切分 ...
for i, micro_batch in enumerate(micro_batches):
# ... 原始 Forward & Backward 逻辑 ...
# ... loss.backward() ...
pass
grad_norm = self._optimizer_step()
+ # 驱动 schedule,对mini batch进行采集,如果想对micro batch进行,则将self.prof_npu.step()移动到micro_batch的循环内
+ self.prof_npu.step()
Megatron 后端
Megatron 后端支持以 Mini-Batch 的粒度进行采集。
修改文件:
verl/workers/actor/megatron_actor.py
class MegatronPPOActor(BasePPOActor):
def update_policy(self, dataloader: Iterable[DataProto]) -> dict:
# ...
+ # 准备 profiler (配置同上,略)
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
+ self.prof_npu = torch_npu.profiler.profile(
+ # ...
+ # 仅采集第一个 Mini Batch 的计算(含所有 Micro-Batch)和一次优化器更新
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/megatron_actor_update_profile", analyse_flag=True)
+ )
+ self.prof_npu.start()
for data in dataloader:
# ... 内部会调用 self.forward_backward_batch 进行计算 ...
# ... metric_micro_batch = self.forward_backward_batch(...)
# ... self.actor_optimizer.step() ...
+ # 驱动 schedule,对mini batch进行采集
+ self.prof_npu.step()