Performance data collection based on FSDP or MindSpeed(Megatron) on Ascend devices(en)
Last updated: 12/20/2025.
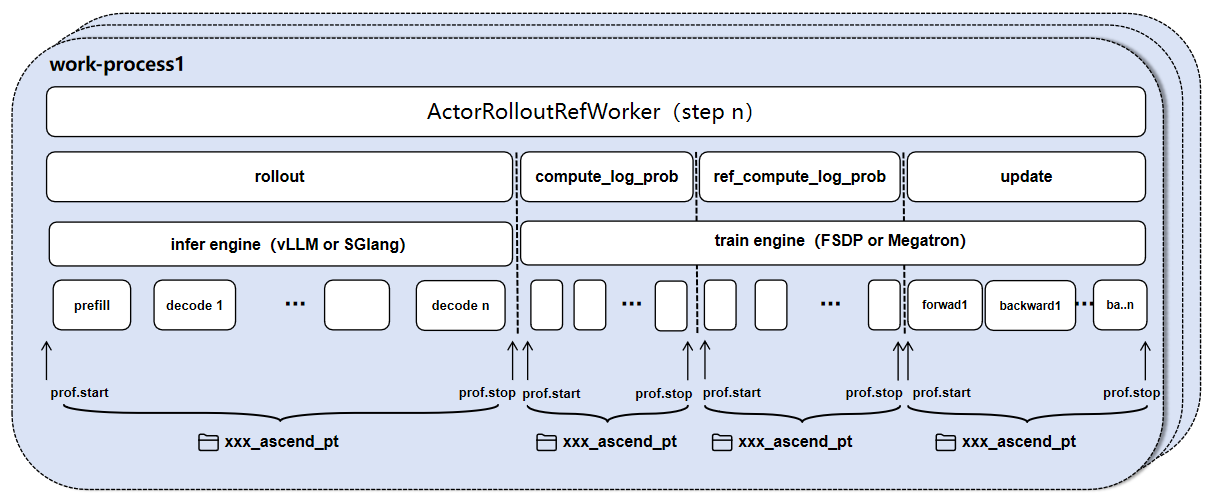
This is a tutorial for data collection using the GRPO or DAPO algorithm based on FSDP or MindSpeed(Megatron) on Ascend devices.
Configuration
Leverage two levels of configuration to control data collection:
Global profiler control: Use parameters in
verl/trainer/config/ppo_trainer.yaml(FSDP) orverl/trainer/config/ppo_megatron_trainer.yaml(MindSpeed) to control the collection mode and steps.Role profile control: Use parameters in each role's
profilefield to control various parameters.
Global collection control
Use parameters in ppo_trainer.yaml to control the collection mode and steps.
global_profiler: Control the ranks and mode of profiling
tool: The profiling tool to use, options are nsys, npu, torch, torch_memory.
steps: This parameter can be set as a list that has collection steps, such as [2, 4], which means it will collect steps 2 and 4. If set to null, no collection occurs.
save_path: The path to save the collected data. Default is "outputs/profile".
Role collection control
In each role's profiler field, you can control the collection mode for that role.
enable: Whether to enable profiling for this role.
all_ranks: Whether to collect data from all ranks.
ranks: A list of ranks to collect data from. If empty, no data is collected.
tool_config: Configuration for the profiling tool used by this role.
Use parameters in each role's profiler.tool_config.npu to control npu profiler behavior:
level: Collection level—options are level_none, level0, level1, and level2
level_none: Disables all level-based data collection (turns off profiler_level).
level0: Collect high-level application data, underlying NPU data, and operator execution details on NPU. After balancing data volume and analytical capability, Level 0 is recommended as the default configuration.
level1: Extends level0 by adding CANN-layer AscendCL data and AI Core performance metrics on NPU.
level2: Extends level1 by adding CANN-layer Runtime data and AI CPU metrics.
contents: A list of options to control the collection content, such as npu, cpu, memory, shapes, module, stack.
npu: Whether to collect device-side performance data.
cpu: Whether to collect host-side performance data.
memory: Whether to enable memory analysis.
shapes: Whether to record tensor shapes.
module: Whether to record framework-layer Python call stack information. It is recommended to use 'module' instead of 'stack' for recording call stack information, as it costs less performance overhead.
stack: Whether to record operator call stack information.
analysis: Enables automatic data parsing.
discrete: Whether to enable discrete mode.
Examples
Disabling collection
global_profiler:
steps: null # disable profile
End-to-End collection
global_profiler:
steps: [1, 2, 5]
save_path: ./outputs/profile
actor_rollout_ref:
actor: # Set actor role profiler collection configuration parameters
profiler:
enable: True
all_ranks: True
tool_config:
npu:
discrete: False
contents: [npu, cpu] # Control collection list, default cpu, npu, can configure memory, shapes, module, etc.
# rollout & ref follow actor settings
Discrete Mode Collection
global_profiler:
steps: [1, 2, 5]
save_path: ./outputs/profile
actor_rollout_ref:
actor:
profiler:
enable: True
all_ranks: True
tool_config:
npu:
discrete: True
contents: [npu, cpu] # Control collection list, default cpu, npu, can configure memory, shapes, module, etc.
# rollout & ref follow actor settings
Visualization
Collected data is stored in the user-defined save_path and can be visualized by using the MindStudio Insight tool.
Additionally, in a Linux environment, the MindStudio Insight tool is provided in the form of a JupyterLab Plugin ,offering a more intuitive and highly interactive user interface. The advantages of the JupyterLab plugin are as follows:
Seamless integration: Supports running the MindStudio Insight tool directly within the Jupyter environment, eliminating the need to switch platforms or copy data from the server, enabling data to be collected and used immediately.
Fast startup: Allows MindStudio Insight to be launched quickly via the JupyterLab command line or graphical interface.
Smooth operation: In a Linux environment, launching MindStudio Insight through JupyterLab effectively alleviates performance lag compared to the full-package communication mode, significantly improving the user experience.
Remote access: Supports remotely launching MindStudio Insight. Users can connect to the service via a local browser for direct visual analysis, reducing the difficulty of uploading and downloading data during large-model training or inference.
If the analysis parameter is set to False, offline parsing is required after data collection:
import torch_npu
# Set profiler_path to the parent directory of the "localhost.localdomain_<PID>_<timestamp>_ascend_pt" folder
torch_npu.profiler.profiler.analyse(profiler_path=profiler_path)
Advanced Guide: Fine-grained Collection
Background and Challenges
Although the configuration-based collection method mentioned above is convenient, it faces challenges in training scenarios with long sequences (Long Context) or large global batch sizes (Large Global Batch Size). Within a complete training step (Step), model computation exhibits high-frequency and repetitive characteristics:
Rollout phase: Sequence generation (Generate Sequence) is an autoregressive process involving thousands of forward computations of the Decoder model.
Training phase: To control peak memory usage, verl typically adopts a Micro-Batch strategy, dividing large data streams into multiple micro-batches for computation.
compute_log_prob (Actor/Ref): Involves multiple rounds of pure forward propagation.
update_policy (Actor/Critic): Involves multiple rounds of forward and backward propagation.
This characteristic leads to massive and repetitive operator records from full profiling. As shown in the image below:
Even with discrete mode enabled, performance data files for a single stage can still reach several TB, leading to parsing failures or visualization tool lag.
Solution: Critical Path Sampling
To solve the above problems, we can adopt a critical path sampling strategy: Based on the API interface provided by torch_npu.profiler, directly modify Python source code to collect only representative data segments (such as specific Decode Steps or the first Micro-Batch).
Important Notes
This chapter involves direct source code modification. It is recommended to back up files before modification and restore them after debugging.
When using code instrumentation for collection, be sure to disable global collection (
global_profiler: steps: null) inppo_trainer.yamlorppo_megatron_trainer.yamlto avoid Profiler conflicts.
1. Fine-grained Collection in Rollout Phase
For vLLM or SGLang inference engines, we can control the schedule parameter to collect model forward propagation performance data for specific tokens.
vLLM Engine
Reference Version: vLLM v0.11.0, vLLM-Ascend v0.11.0rc1
Modified File:
vllm-ascend/vllm_ascend/worker/worker_v1.py
class NPUWorker(WorkerBase):
def __init__(self, *args, **kwargs):
# ... existing code ...
+ # Initialize profiler
+ import torch_npu
+ experimental_config = torch_npu.profiler._ExperimentalConfig(
+ profiler_level=torch_npu.profiler.ProfilerLevel.Level1,
+ export_type=torch_npu.profiler.ExportType.Db, # You can choose torch_npu.profiler.ExportType.Text format
+ )
+ self.profiler_npu = torch_npu.profiler.profile(
+ activities=[torch_npu.profiler.ProfilerActivity.CPU, torch_npu.profiler.ProfilerActivity.NPU],
+ with_modules=False, # Collect call stack
+ profile_memory=False, # Collect memory
+ experimental_config=experimental_config,
+ # Skip first step, warmup one step, collect 3 steps, repeat 1 time. If you want to collect decode steps 30~70, set schedule=torch_npu.profiler.schedule(wait=29, warmup=1, active=30, repeat=1)
+ schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/vllm_profile", analyse_flag=True) # Data save path and whether to parse online
+ )
+ self.profiler_npu.start()
# ... existing code ...
def execute_model(self, scheduler_output=None, intermediate_tensors=None, **kwargs):
# ... existing code ...
output = self.model_runner.execute_model(scheduler_output,
intermediate_tensors)
+ self.profiler_npu.step() # Drive schedule to collect partial decode steps
# ... existing code ...
SGLang Engine
Reference Version: SGLang master branch
Modified File:
sglang/python/sglang/srt/model_executor/model_runner.py
# ... existing imports ...
+ import torch_npu
class ModelRunner:
def __init__(self, *args, **kwargs):
# ... existing init code ...
+ # Initialize profiler (same configuration as above, omitted)
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
+ self.profiler_npu = torch_npu.profiler.profile(
+ # ...
+ # Skip first step, warmup one step, collect 3 steps, repeat 1 time.
+ schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/sglang_profile", analyse_flag=True)
+ )
+ self.profiler_npu.start()
def forward(self, forward_batch, **kwargs):
# ... existing code ...
+ self.profiler_npu.step() # Drive schedule to collect partial decode steps
return output
2. Fine-grained Collection in compute_log_prob (Actor & Ref) Phase
This phase computes probability distributions for new and old policies.
FSDP Backend
The FSDP backend allows fine-grained control at the Micro-Batch level.
Modified File:
verl/workers/actor/dp_actor.py
# ... import dependencies ...
+ import torch_npu
class DataParallelPPOActor(BasePPOActor):
def compute_log_prob(self, data: DataProto, calculate_entropy=False) -> torch.Tensor:
+ role = "Ref" if self.actor_optimizer is None else "Actor"
+ # Prepare profiler (same configuration as above, omitted)
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
+ self.prof_npu = torch_npu.profiler.profile(
+ # ...
+ # wait=0, warmup=0, active=1: directly collect first micro-batch
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(f"./outputs/{role}_compute_log_prob", analyse_flag=True)
+ )
+ # This function is shared by ref and actor, set role flag to distinguish. If you want to collect actor_compute_log_prob, set if role=="Actor":
+ if role=="Ref":
+ self.prof_npu.start()
for micro_batch in micro_batches:
# ... original computation logic ...
with torch.no_grad():
entropy, log_probs = self._forward_micro_batch(...)
+ # Drive schedule to collect micro batch
+ if role=="Ref":
+ self.prof_npu.step()
# ...
Megatron Backend
The Micro-Batch scheduling in the Megatron backend is managed internally by the framework and does not currently support fine-grained collection at the Micro-Batch level through simple code instrumentation. It is recommended to use global configuration for collection.
3. Fine-grained Collection in update_policy (Actor & Critic) Phase
The Update phase includes forward and backward propagation.
FSDP Backend
The FSDP backend supports collection at both Mini-Batch and Micro-Batch granularities.
Modified File:
verl/workers/actor/dp_actor.py
# ... import dependencies ...
+ import torch_npu
class DataParallelPPOActor(BasePPOActor):
def update_policy(self, data: DataProto):
+ # Prepare profiler (same configuration as above, omitted)
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
+ self.prof_npu = torch_npu.profiler.profile(
+ # ...
+ # Only collect first Mini Batch (including all Micro-Batch computations and one optimizer update)
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/fsdp_actor_update_profile", analyse_flag=True)
+ )
+ self.prof_npu.start()
# ... PPO Epochs loop ...
for _ in range(self.config.ppo_epochs):
# ... Mini Batch loop ...
for batch_idx, mini_batch in enumerate(mini_batches):
# ... mini_batches split ...
for i, micro_batch in enumerate(micro_batches):
# ... Original Forward & Backward logic ...
# ... loss.backward() ...
pass
grad_norm = self._optimizer_step()
+ # Drive schedule to collect mini batch, if you want micro batch collection, move self.prof_npu.step() inside the micro_batch loop
+ self.prof_npu.step()
Megatron Backend
The Megatron backend supports collection at the Mini-Batch granularity.
Modified File:
verl/workers/actor/megatron_actor.py
class MegatronPPOActor(BasePPOActor):
def update_policy(self, dataloader: Iterable[DataProto]) -> dict:
# ...
+ # Prepare profiler (same configuration as above, omitted)
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
+ self.prof_npu = torch_npu.profiler.profile(
+ # ...
+ # Only collect computation of first Mini Batch (including all Micro-Batches) and one optimizer update
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/megatron_actor_update_profile", analyse_flag=True)
+ )
+ self.prof_npu.start()
for data in dataloader:
# ... internally calls self.forward_backward_batch for computation ...
# ... metric_micro_batch = self.forward_backward_batch(...)
# ... self.actor_optimizer.step() ...
+ # Drive schedule to collect mini batch
+ self.prof_npu.step()