快速开始
备注
阅读本篇前,请确保已按照 安装教程 准备好昇腾环境及 LLaMA-Factory !
本教程聚焦大语言模型(Large Language Model,LLM)的微调过程,以 Qwen1.5-7B 模型为例,讲述如何使用 LLaMA-Factory 在昇腾 NPU 上进行 LoRA 微调及推理。
本篇将使用到 DeepSpeed 和 ModelScope,请使用以下指令安装:
pip install -e ".[deepspeed,modelscope]" -i https://pypi.tuna.tsinghua.edu.cn/simple
环境变量配置
通过环境变量设置单卡 NPU,并使用 ModelScope 下载模型/数据集:
export ASCEND_RT_VISIBLE_DEVICES=0
export USE_MODELSCOPE_HUB=1
基于 LoRA 的模型微调
yaml 配置文件
在 LLAMA-Factory 目录下,创建如下 qwen1_5_lora_sft_ds.yaml:
展开 qwen1_5_lora_sft_ds.yaml
### model
model_name_or_path: qwen/Qwen1.5-7B
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: q_proj,v_proj
### ddp
ddp_timeout: 180000000
deepspeed: examples/deepspeed/ds_z0_config.json
### dataset
dataset: identity,alpaca_en_demo
template: qwen
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/Qwen1.5-7B/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 0.0001
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
fp16: true
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
开启微调
使用 torchrun 启动微调,微调涉及的所有参数均在 yaml 配置文件 中设置。
torchrun --nproc_per_node 1 \
--nnodes 1 \
--node_rank 0 \
--master_addr 127.0.0.1 \
--master_port 7007 \
src/train.py qwen1_5_lora_sft_ds.yaml
备注
nproc_per_node, nnodes, node_rank, master_addr, master_port 为 torchrun 所需参数,其详细含义可参考 PyTorch 官方文档。
如正常输出模型加载、损失 loss 等日志,即说明成功微调。如需NPU 多卡分布式训练请参考 单机多卡微调
动态合并 LoRA 的推理
经 LoRA 微调后,通过 llamafactory-cli chat 使用微调后的模型进行推理,指定 adapter_name_or_path 参数为 LoRA 微调模型的存储路径:
llamafactory-cli chat --model_name_or_path qwen/Qwen1.5-7B \
--adapter_name_or_path saves/Qwen1.5-7B/lora/sft \
--template qwen \
--finetuning_type lora
备注
确保微调及推理阶段使用同一 prompt 模板 template
接下来即可在终端使用微调的模型进行问答聊天了!使用 Ctrl+C 或输入 exit 退出该问答聊天,如下图所示,为在 NPU 成功推理的样例:
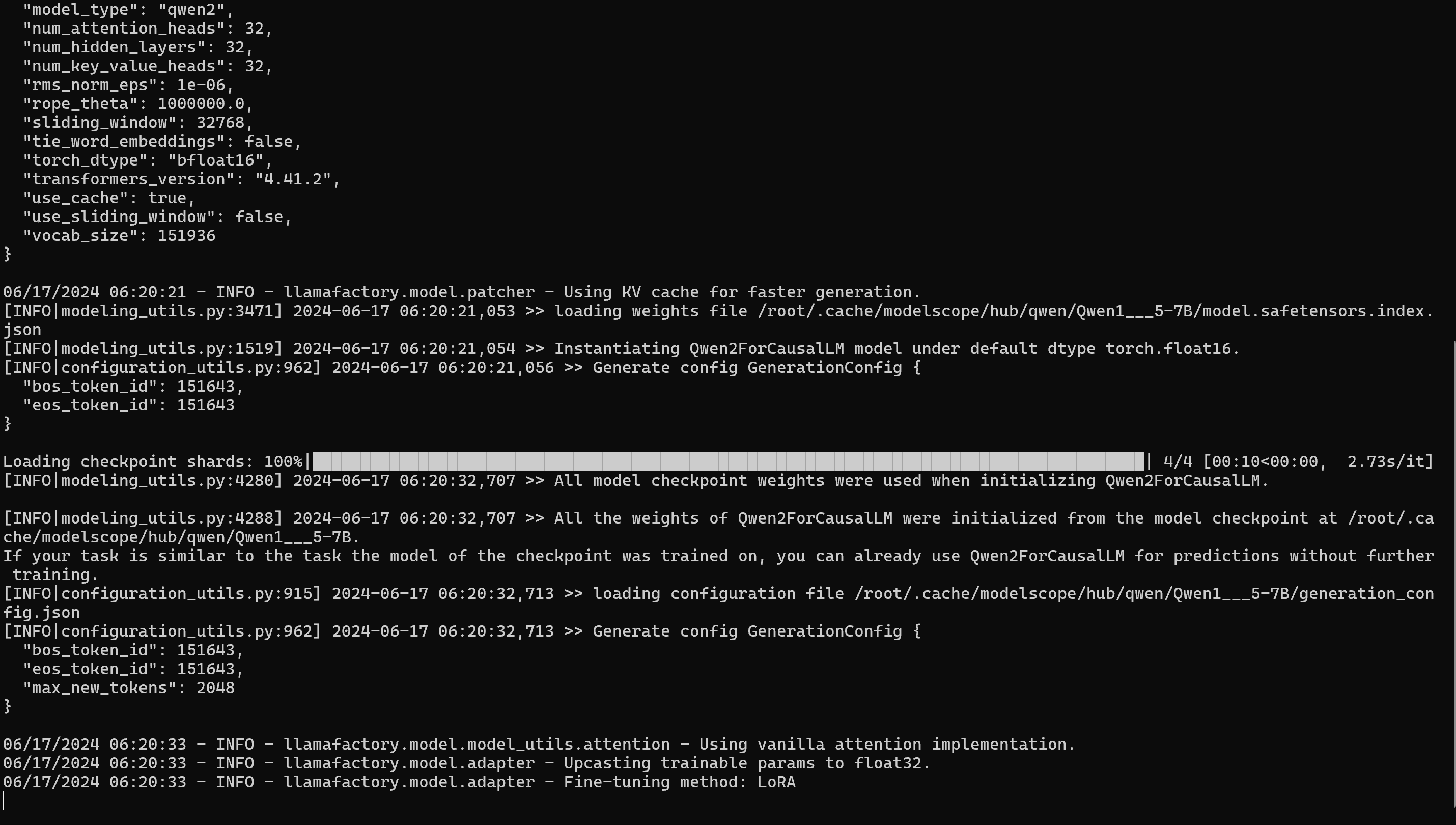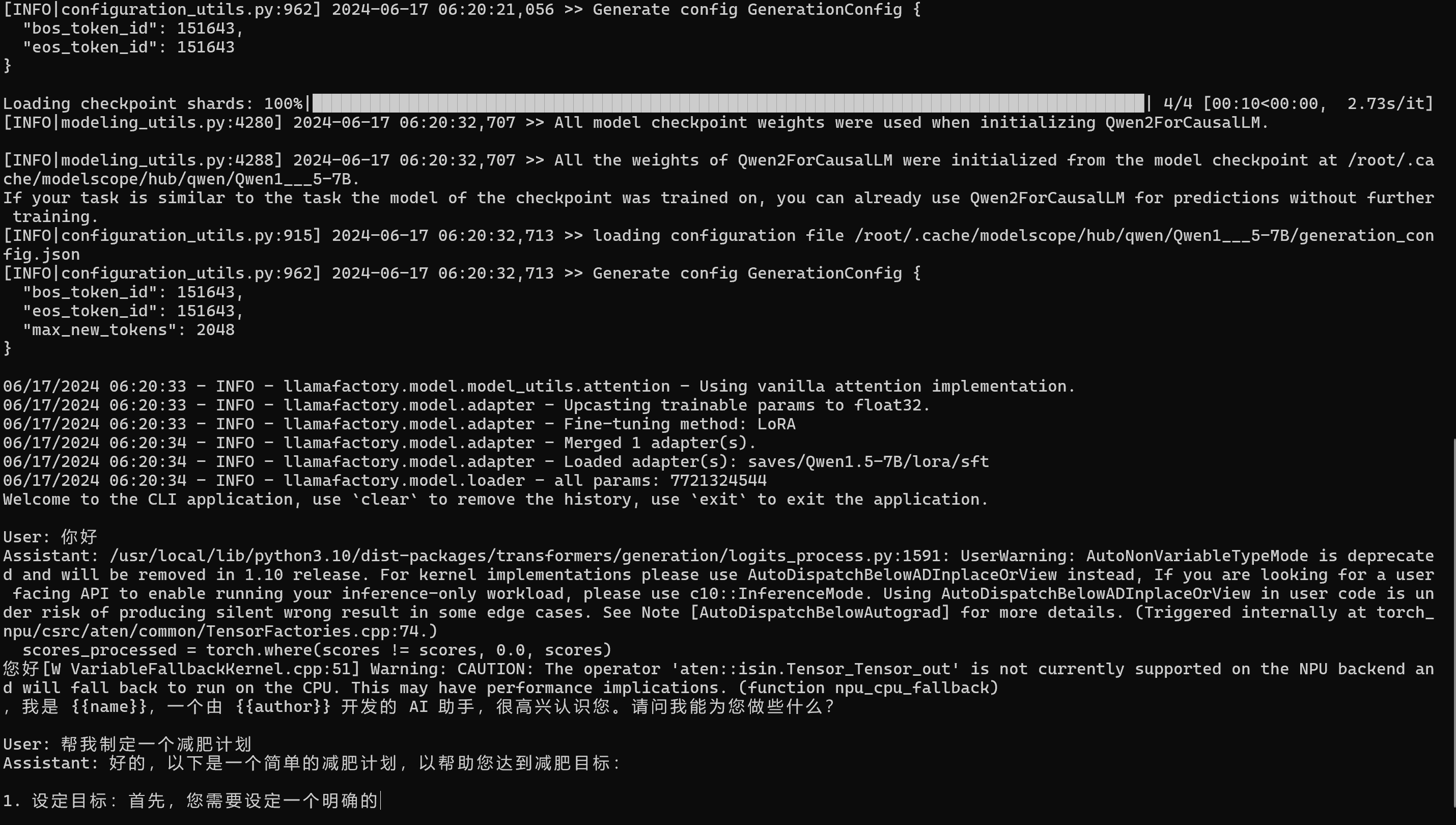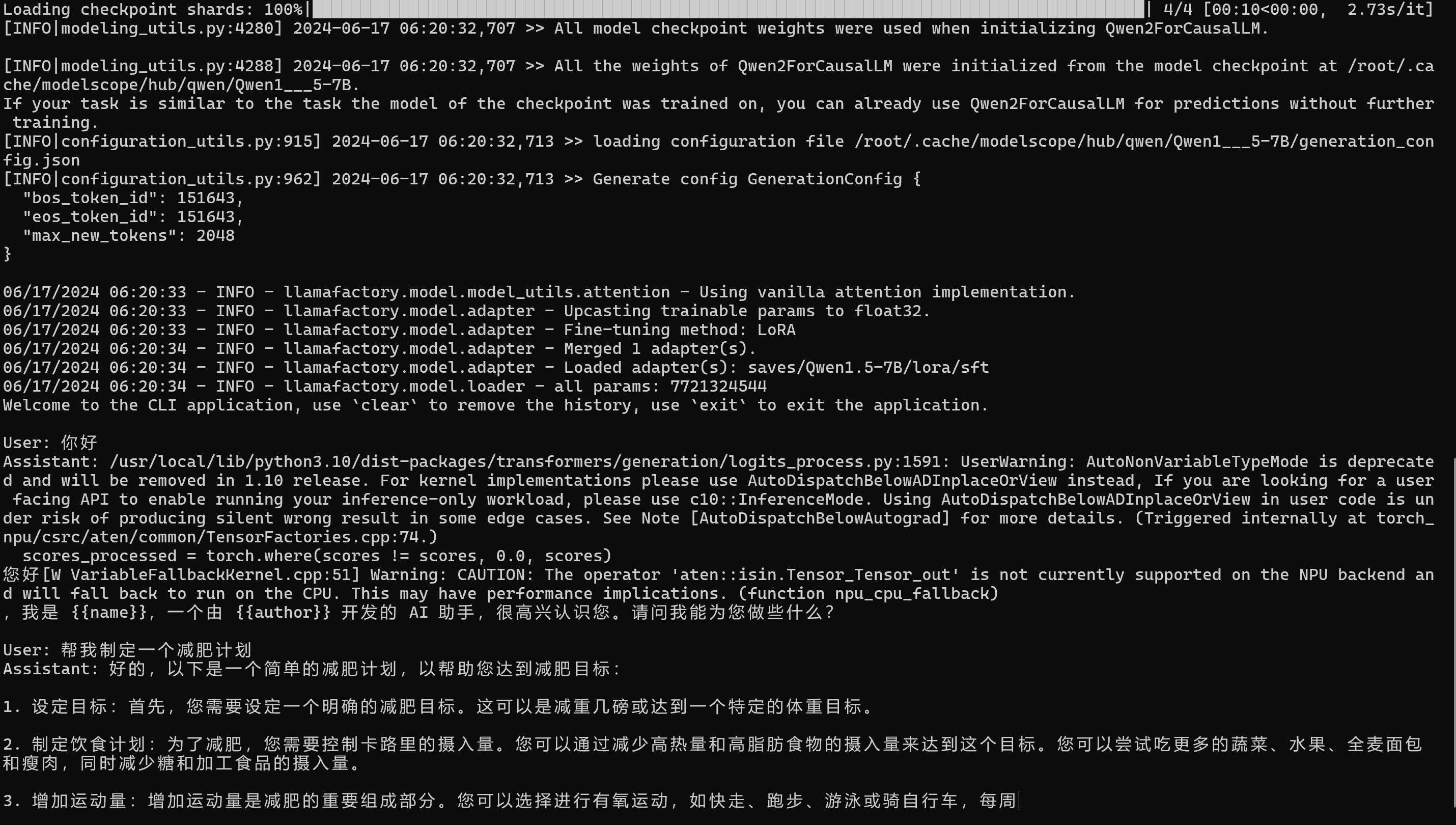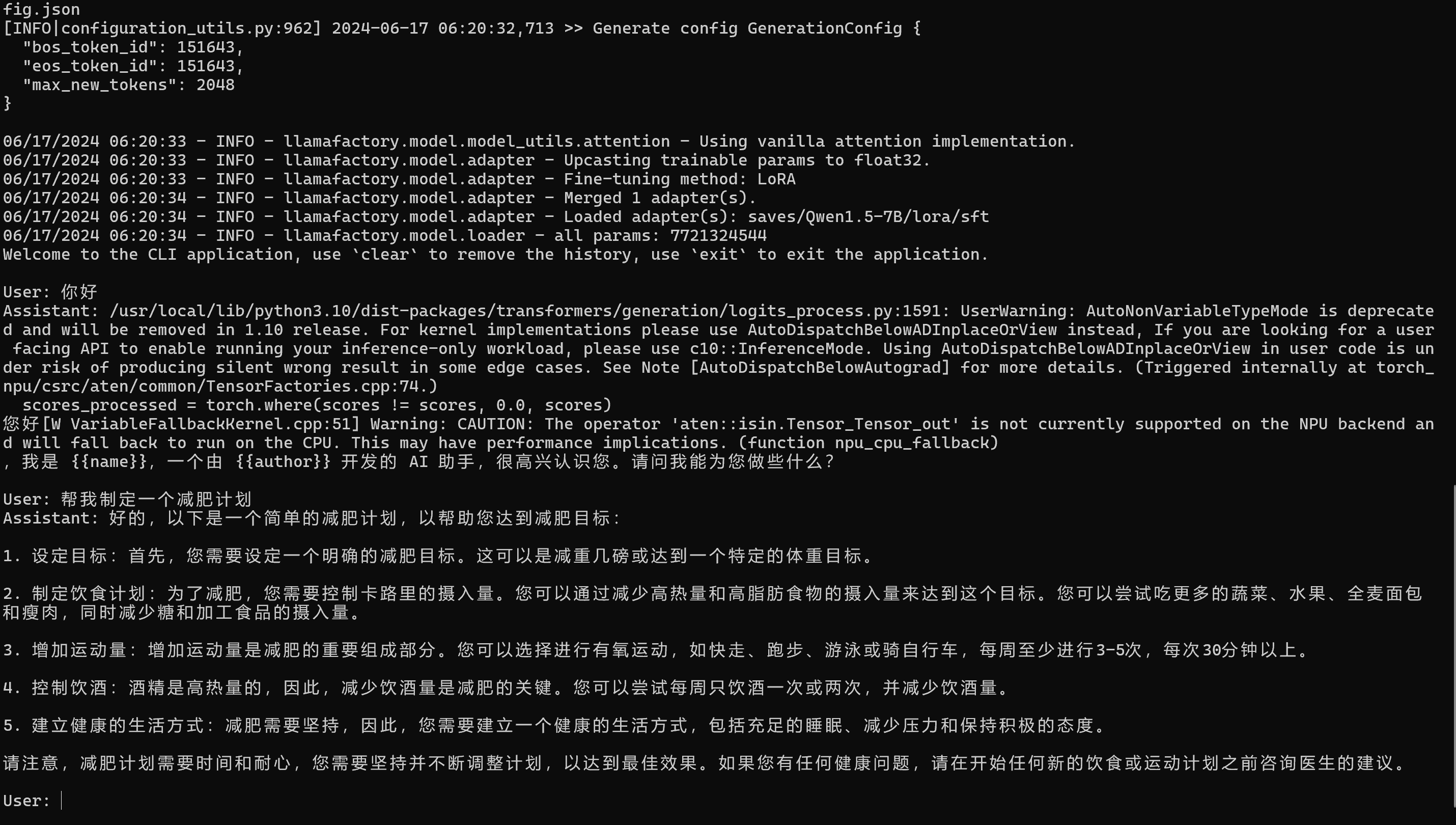
备注
第一轮问答会有一些 warning 告警,这是由于 transformers 库更新所致,不影响推理的正常运行,请忽略
完整脚本
推理及微调脚本
使用 Qwen1.5-7B 模型微调和推理的完整脚本如下:
# use modelscope
export USE_MODELSCOPE_HUB=1
# specify NPU
export ASCEND_RT_VISIBLE_DEVICES=0
### qwen/Qwen1.5-7B
### finetune
torchrun --nproc_per_node 1 \
--nnodes 1 \
--node_rank 0 \
--master_addr 127.0.0.1 \
--master_port 7007 \
src/train.py <your_path>/qwen1_5_lora_sft_ds.yaml
### inference -- chat
llamafactory-cli chat --model_name_or_path qwen/Qwen1.5-7B \
--adapter_name_or_path saves/Qwen1.5-7B/lora/sft \
--template qwen \
--finetuning_type lora
也可以使用vllm-ascend进行推理加速:
备注
先安装vllm-ascend,见`vllm-ascend 官方安装指南:<https://vllm-ascend.readthedocs.io/en/latest/installation.html>`
# use modelscope
export USE_MODELSCOPE_HUB=1
# specify NPU
export ASCEND_RT_VISIBLE_DEVICES=0
# Set `max_split_size_mb` to reduce memory fragmentation and avoid out of memory
export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256
# Since the vllm service is started by pulling up a child process, you need to use the spawn method to create a vllm-serve process
export VLLM_WORKER_MULTIPROC_METHOD=spawn
### inference -- chat
llamafactory-cli chat --model_name_or_path qwen/Qwen1.5-7B \
--adapter_name_or_path saves/Qwen1.5-7B/lora/sft \
--template qwen \
--finetuning_type lora\
--infer_backend vllm