全流程昇腾实践
开始本篇之前,请阅读 LLaMA-Factory QuickStart 了解 LLaMA-Factory 及其主要功能的用法, 并参考 安装指南 及 快速开始 完成基本的环境准备、LLaMA-Factory 安装及简单的微调和推理功能。 本篇在此基础上,以 Qwen1.5-7B 模型为例,帮助开发者在昇腾 NPU 上使用 LLaMA-Factory 更多实用特性。
LLaMA-Factory QuickStart 中详解了下列 9 种功能,本教程为在 NPU 上全流程实践示例, 有关功能及参数的详细解析请参考 LLaMA-Factory QuickStart
原始模型直接推理
自定义数据集构建
基于 LoRA 的 sft 指令微调
动态合并 LoRA 的推理
批量预测和训练效果评估
LoRA模型合并导出
一站式 webui board 的使用
API Server的启动与调用
大模型主流评测 benchmark
前置准备
安装准备
请确认已按照 安装指南 安装 CANN 和 LLaMA-Factory 并完成安装校验。
配置文件准备
本示例中用到的参数配置文件与快速开始 qwen1_5_lora_sft_ds.yaml 中一致,可参考快速开始。
原始模型直接推理
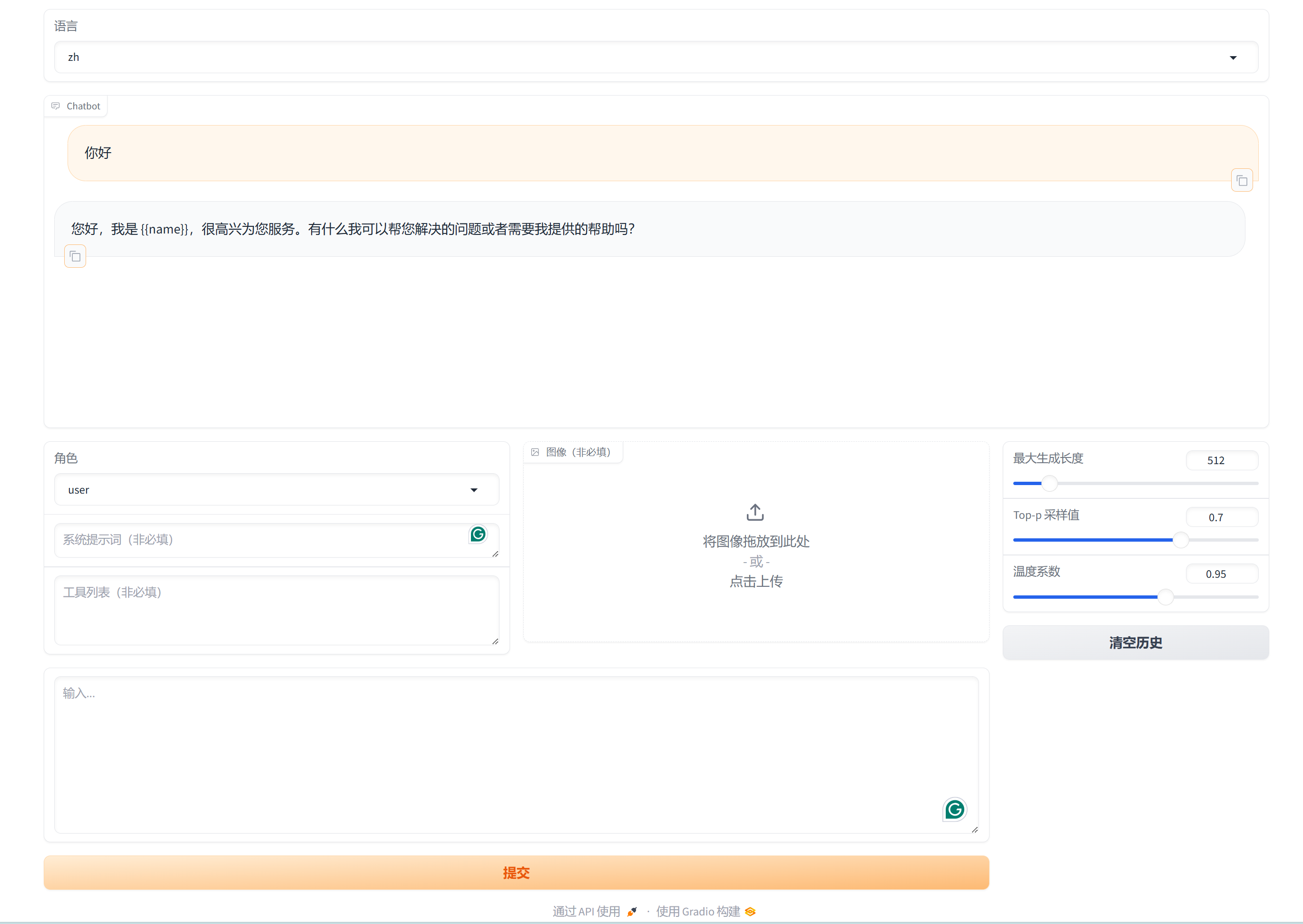
验证 LLaMA-Factory 在昇腾 NPU 上推理功能是否正常:
1ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli webchat --model_name_or_path qwen/Qwen1.5-7B \
2 --adapter_name_or_path saves/Qwen1.5-7B/lora/sft \
3 --template qwen \
4 --finetuning_type lora
如下图所示可正常进行对话,即为可正常推理:
自定义数据集构建
本篇用到的数据集为 LLaMA-Factory 自带的 identity 和 alpaca_en_demo,对 identity 数据集进行如下全局替换即可实现定制指令:
{{name}}替换为Ascend-helper{{author}}替换为Ascend
更多自定义数据集的构建请参考 官方数据集构造指引 。
基于 LoRA 的 sft 指令微调
在 快速开始 中,已经尝试过使用 src/train.py 为入口的微调脚本,本篇中均使用 llamafactory-cli 命令启动微调、推理等程序。
1ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli train <your_path>/qwen1_5_lora_sft_ds.yaml
动态合并 LoRA 的推理
1ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli chat --model_name_or_path qwen/Qwen1.5-7B \
2 --adapter_name_or_path saves/Qwen1.5-7B/lora/sft \
3 --template qwen \
4 --finetuning_type lora
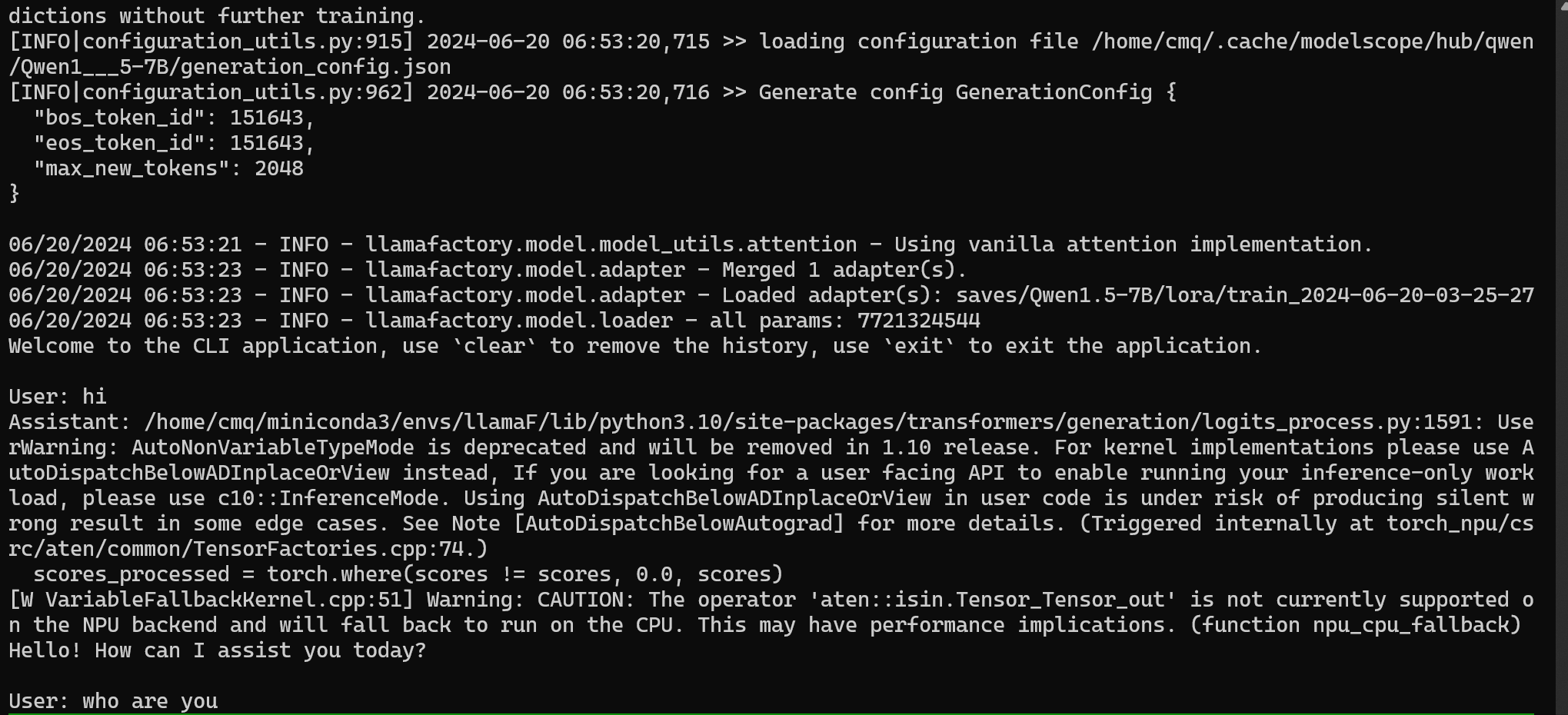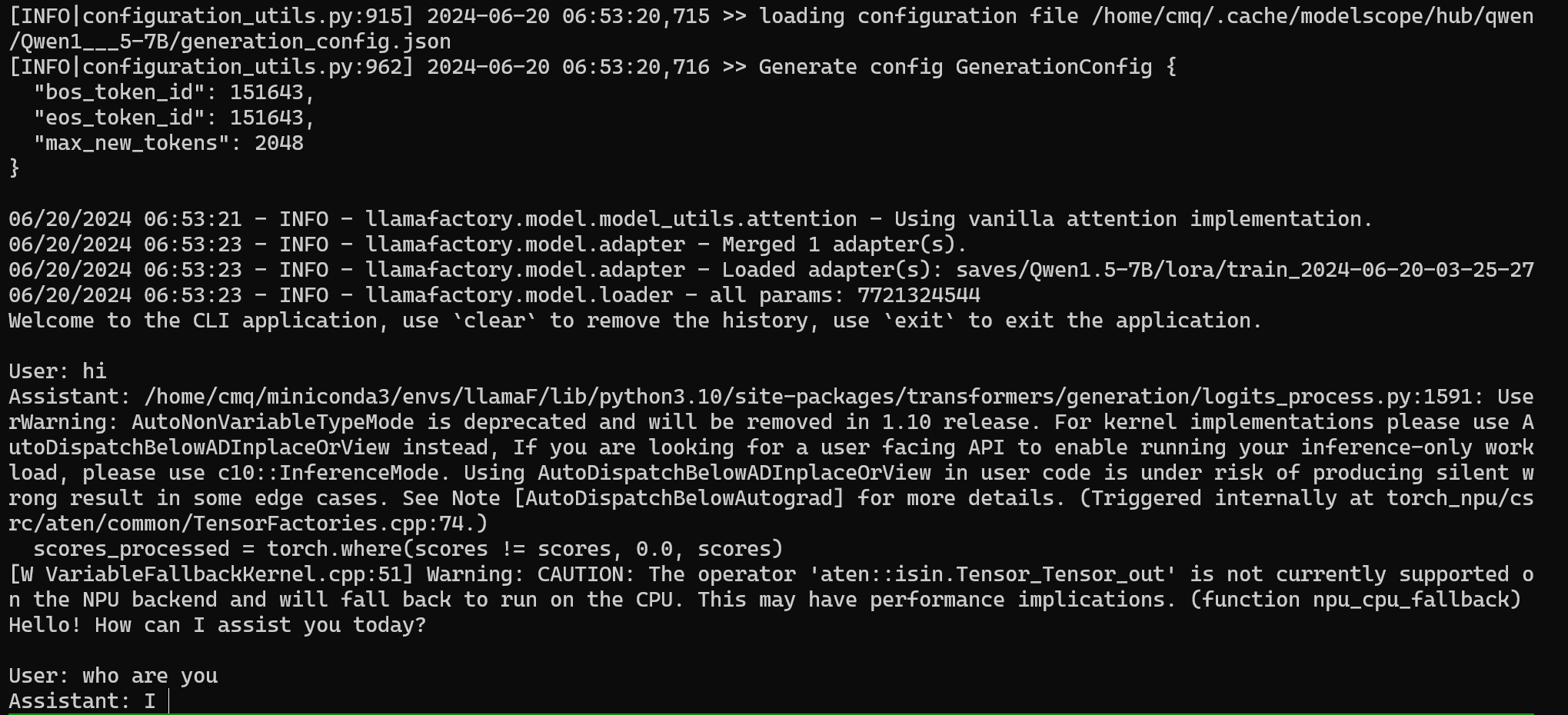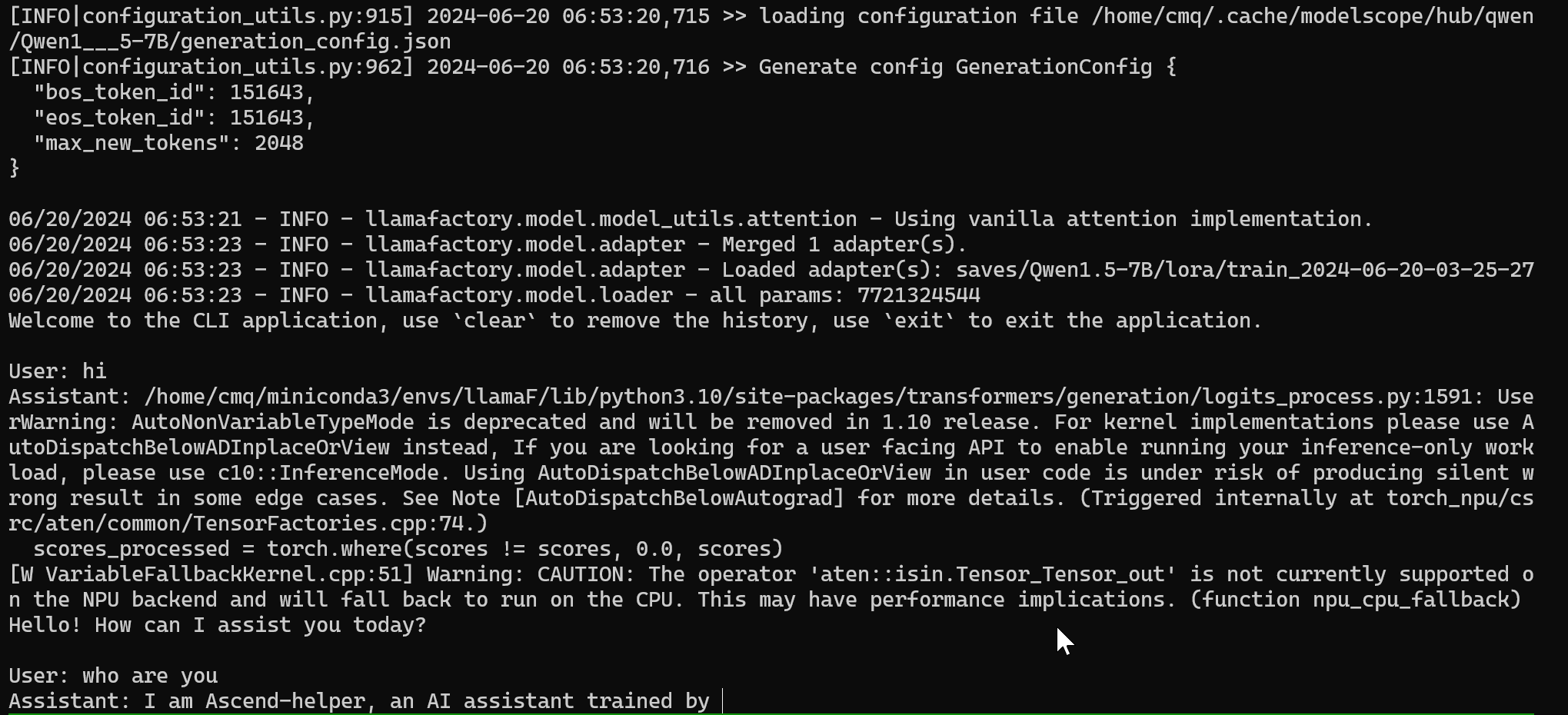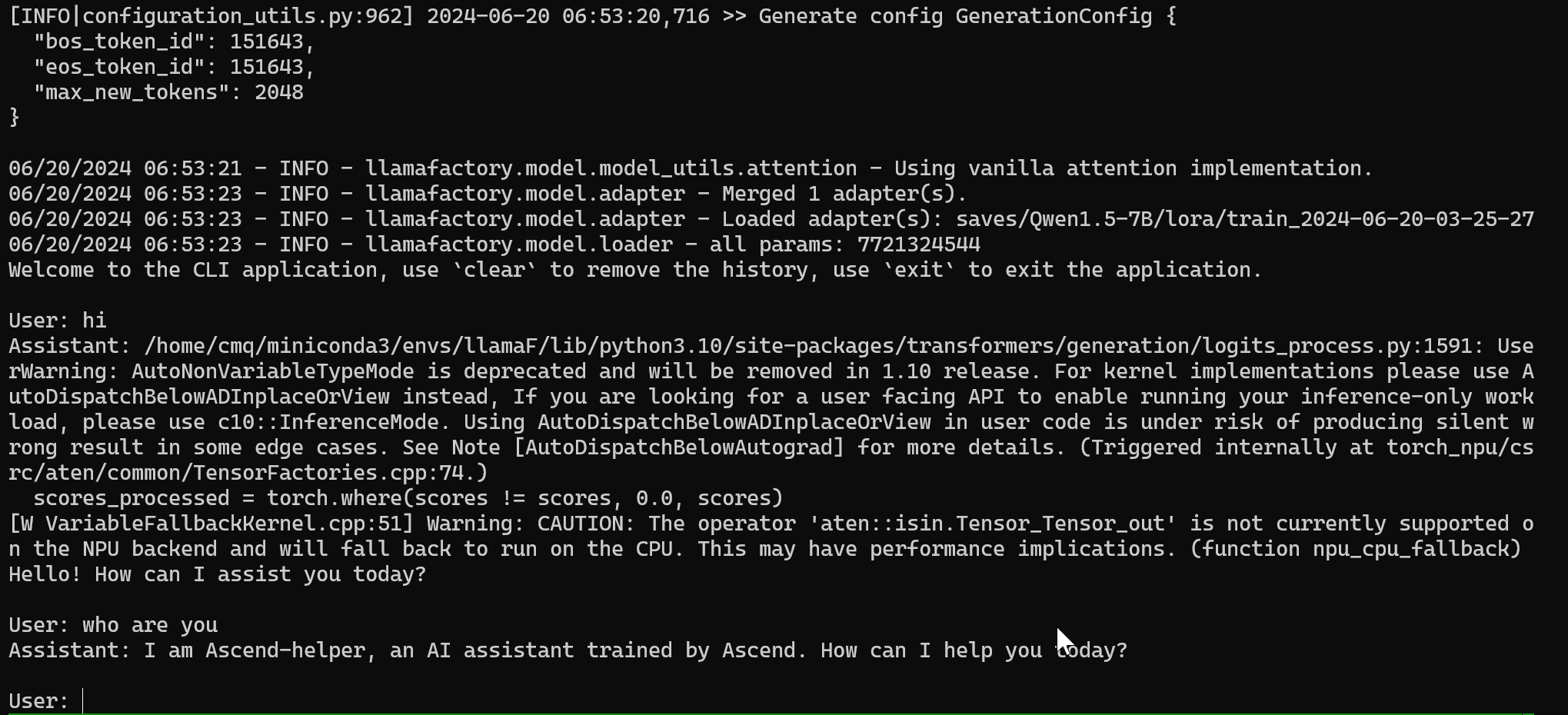
通过询问大模型是谁检验 sft 指令微调的成果,如下图,大模型回答自己是 Ascend-helper 说明 sft 成功,如失败,可返回 基于 LoRA 的 sft 指令微调 增加训练轮数重新训练。
批量预测和训练效果评估
使用批量预测和评估前,需先安装 jieba、rouge-chinese、nltk 三个库:
1pip install jieba,rouge-chinese,nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
然后使用以下指令对微调后的模型在 alpaca_gpt4_zh 和 identity 数据集上进行批量预测和效果评估:
1ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli train \
2 --stage sft \
3 --do_predict \
4 --model_name_or_path qwen/Qwen1.5-7B \
5 --adapter_name_or_path ./saves/Qwen1.5-7B/lora/sft \
6 --dataset alpaca_gpt4_zh,identity \
7 --dataset_dir ./data \
8 --template qwen \
9 --finetuning_type lora \
10 --output_dir ./saves/Qwen1.5-7B/lora/predict \
11 --overwrite_cache \
12 --overwrite_output_dir \
13 --cutoff_len 1024 \
14 --preprocessing_num_workers 16 \
15 --per_device_eval_batch_size 1 \
16 --max_samples 20 \
17 --predict_with_generate
完成批量预测与评估后,在指定的输出路径下会看到以下文件:
all_results.json
generated_predictions.jsonl
predict_results.json
trainer_log.jsonl
generated_predictions.json 中为所有测试样本的输入提示词 prompt、标签 label 和模型输出预测结果 predict,下面是其中一个示例:
{"prompt": "system\nYou are a helpful assistant.\nuser\n保持健康的三个提示。\nassistant\n", "label": "以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。", "predict": "保持健康的三个提示包括:1. 均衡饮食:饮食应包括各种食物,如蔬菜、水果、全麦面包、蛋白质和健康脂肪,以满足身体的营养需求。\n2. 锻炼:每周至少进行150分钟的中等强度有氧运动,如快走、跑步、游泳或骑自行车,以及至少两次力量训练,以帮助维持身体健康。\n3. 睡眠:保持规律的睡眠习惯,每晚至少睡7-8小时,以帮助身体恢复和充电。"}
predict_results.json 中即为训练效果评估所得结果:
{
"predict_bleu-4": 50.941235,
"predict_rouge-1": 65.7085975,
"predict_rouge-2": 52.576409999999996,
"predict_rouge-l": 60.487535,
"predict_runtime": 196.1634,
"predict_samples_per_second": 0.204,
"predict_steps_per_second": 0.204
}
LoRA 模型合并导出
LoRA 模型合并和导出时,可通过指定 export_device 参数为 auto 来自动检测当前加速卡环境,
启用 NPU 作为导出设备:
1ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli export \
2 --model_name_or_path qwen/Qwen1.5-7B \
3 --adapter_name_or_path ./saves/Qwen1.5-7B/lora/sft \
4 --template qwen \
5 --finetuning_type lora \
6 --export_dir ./saves/Qwen1.5-7B/lora/megred-model-path \
7 --export_size 2 \
8 --export_device auto \
9 --export_legacy_format False
一站式 webui board 的使用
使用 webui 可零代码实现以上功能,启动命令如下:
1ASCEND_RT_VISIBLE_DEVICES=0 GRADIO_SHARE=0 GRADIO_SERVER_PORT=7007 GRADIO_SERVER_NAME="0.0.0.0" llamafactory-cli webui
在 webui 实现 Qwen1.5-7B 模型的 LoRA 模型微调、动态推理和模型导出的操作示例:
API Server的启动与调用
API_PORT 为 API 服务的端口号,可替换为自定义端口。通过以下命令启动 API 服务:
1ASCEND_RT_VISIBLE_DEVICES=0 API_PORT=7007 llamafactory-cli api \
2 --model_name_or_path qwen/Qwen1.5-7B \
3 --adapter_name_or_path ./saves/Qwen1.5-7B/lora/sft \
4 --template qwen \
5 --finetuning_type lora
终端输出如下关键信息时,即可在下游任务重通过 API 调用 Qwen1.5-7B
1Visit http://localhost:7007/docs for API document.
2INFO: Started server process [2261535]
3INFO: Waiting for application startup.
4INFO: Application startup complete.
5INFO: Uvicorn running on http://0.0.0.0:7007 (Press CTRL+C to quit)
使用 API 调用 Qwen1.5-7B 实现问答聊天的示例代码,通过 message 传入您的问题:
1import os
2from openai import OpenAI
3from transformers.utils.versions import require_version
4
5require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")
6
7if __name__ == '__main__':
8 # change to your custom port
9 port = 7007
10 client = OpenAI(
11 api_key="0",
12 base_url="http://localhost:{}/v1".format(os.environ.get("API_PORT", 7007)),
13 )
14 messages = []
15 messages.append({"role": "user", "content": "hello, what is Ascend NPU"})
16 result = client.chat.completions.create(messages=messages, model="test")
17 print(result.choices[0].message)
执行成功后可在终端看到如下输出,Qwen1.5-7B 正确介绍了 Ascend NPU:
ChatCompletionMessage(content='The Ascend NPU, or Neural Processing Unit, is an AI chip developed by Huawei that is designed to accelerate the performance of deep learning and artificial intelligence workloads. It is specifically designed to be energy-efficient, and is intended to be used in a wide range of devices, from smartphones to data centers. The Ascend NPU is designed to support a variety of AI workloads, including object detection, natural language processing, and speech recognition.', role='assistant', function_call=None, tool_calls=None)
进阶-大模型主流评测 benchmark
通过以下指令启动对 Qwen1.5-7B 模型在 mmlu 数据集的评测:
1llamafactory-cli eval \
2 --model_name_or_path qwen/Qwen1.5-7B \
3 --template fewshot \
4 --task mmlu \
5 --split validation \
6 --lang en \
7 --n_shot 5 \
8 --batch_size 1
评测完成后,终端输出的评测结果如下,与 Qwen1.5-7B 官方报告对齐:
Average: 61.79
STEM: 54.83
Social Sciences: 73.00
Humanities: 55.02
Other: 67.32