快速开始
备注
阅读本篇前,请确保已按照 安装指南 准备好昇腾环境及stable-diffusion-webui!
参数说明
主要参数
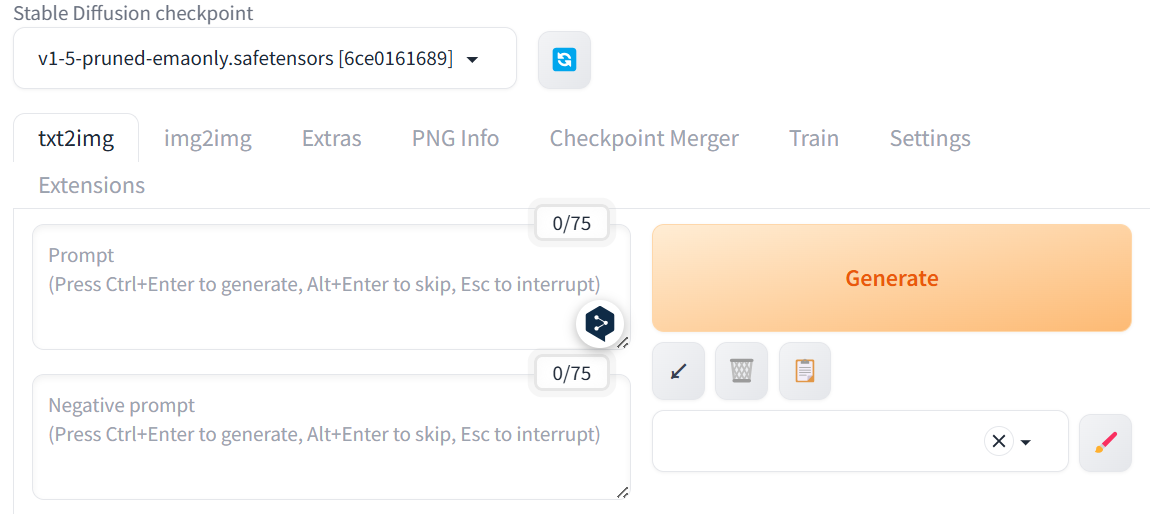
Stable Diffusion checkpoint
用于更换模型文件,v1-5-pruned-emaonly.safetensors为stable-diffusion-webui的默认模型文件,更换其他模型文件需自行下载。
Prompt
正面提示词,构成提示词的基础,直接描述想要生成的图像内容、风格、情感等作为元素权重的关键词,让AI更倾向于在绘图中绘制和Prompt的内容相关的元素。
Negative Prompt
反向提示词,作用与Prompt相反,反向加权的权重关系,减少某些元素出现的频率,从而约束AI的行为。
Generate
即开始生成图片按钮。
其他参数
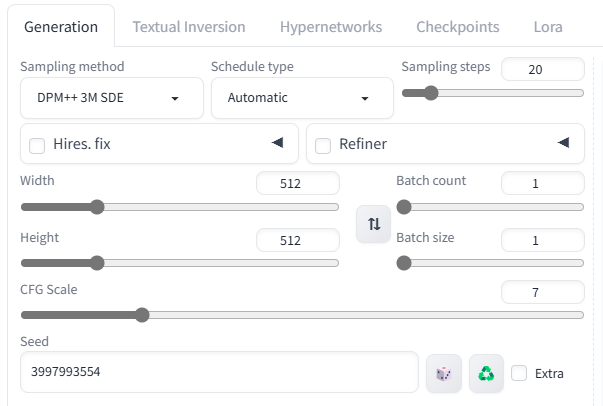
Sampling method
即采样方法,采样方法本身并没有绝对意义上的优劣之分,只有是否合适这一说:
Euler方法,是比较成熟的一种采样方法,效果比较稳定
LMS:这个是最小均方误差算法,这是一个自适应的滤波器。
Heun:这个是建立在欧拉方法基础上的一个在给定初始条件下求解常微分方程的方法。
DPM:这是一个深度学习的PDE(偏微分方程)增强方法。
Sampling Steps
即采样步长,它并不是越大越好,同样也不是越小越好,太小采样的随机性会很高,太大采样的效率会很低,拒绝概率高。
seed
seed即为种子,-1时生成一个随机数,这个随机数影响画面的内容,相当于手动初始了神经网络的权重参数,在配合其他相同参数的情况下能得到一个极其类似的结果。
Width & Height
生成图片的宽和高
文生图
文生图就是根据文字生成图片,主要操作为点击Stable Diffusion checkpoint选择模型,在Prompt和Negative Prompt填入提示词,点击Generate按钮生成图片。
以下是根据提示词生成的图片:
Prompt:a cute cat
Negative Prompt:deformed, lowres, bad anatomy

图生图
图生图(img2img)是让AI参照现有的图片生图:
如上传一张真人照片,让AI把他改绘成动漫人物;上传画作线稿,让AI自动上色;上传一张黑白照,让AI把它修复成彩色相片。
参数和操作与文生图重叠,这里不在赘述。
以下是图片生成的效果:
Prompt:a cute cat wear a hat
Negative Prompt:deformed, lowres, bad anatomy
